FileClap: Clear the paperwork off the table
No more paper chaos! FileClap helps you easily organize photos, receipts, and important documents. Securely stored and accessible from anywhere—for a stress-free daily life with more clarity!
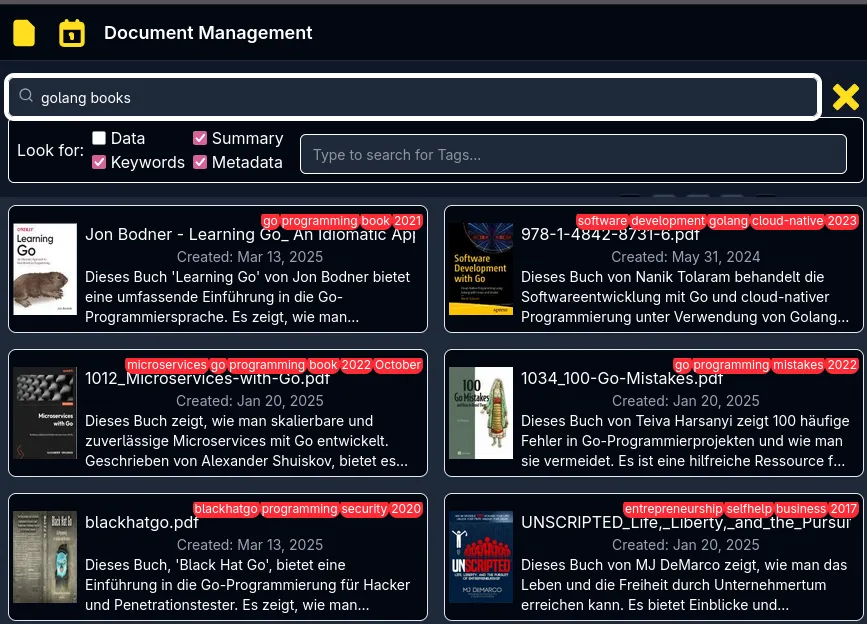
Advanced Search Capabillites using Vector embeddings.
Architecture and Technologies
General
FileClap is built on golang with a-h/templ as a frontend technology, works with any s3 compatible Objectstorage. Keycloak is used for the authentication migrated from a previously self contained login flow.
Redis is used to allow scalability in a microservice deployment.
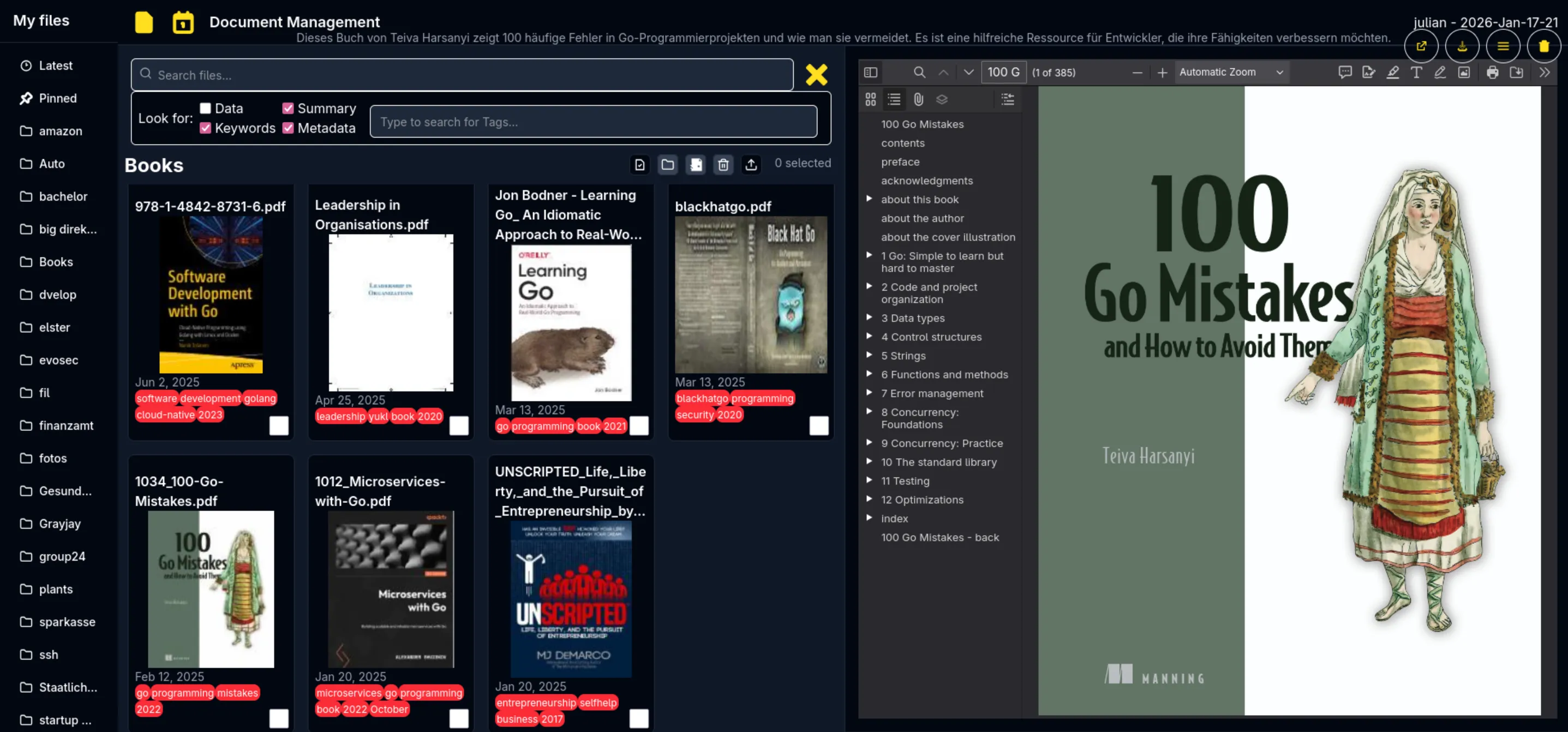
A seperate Thumbnail Generator was created in addition to create thumbnails for all types of files. Because it uses a large libraries like ffmped and pdf parsers, it was extracted into a seperate service. This allows the main service to be a small 32mb docker image, while the thumbnail generator is at 163mb after heavy optimization from an original 1gb+ container, the connection between the fileclap and the thumbnail generator runs over grpc.
To allow for the vector embeddings that enable the semantic search, a migration from sqlite to postgres has taken place.
For Observability OpenTelemetry is used on a function level basis, focussing on heavy operations like storage actions, database accessing and using the ocr service:
func (c *S3client) UploadObject(ctx context.Context, key string, body io.Reader, contentType string, user models.User) error {
//add new span for this function
tracer := otel.Tracer("fileclap_" + Version)
ctx, span := tracer.Start(ctx, "s3.UploadObject")
defer span.End()
_, err := c.Client.PutObject(ctx, &s3.PutObjectInput{
Bucket: aws.String(user.ID.String()),
Key: aws.String(key),
Body: body,
ContentType: aws.String(contentType),
})
if err != nil {
//add error to span in cause something breaks
span.RecordError(err)
return err
}
return nil
}To minimize risks of data collisions and chances of different tenants accessing data of each other, each tenant has been given a s3-bucket that is just his user id. in the same way are all file / web requests handled:
https://fileclap.com/{userid}/operation/{fileid}/etc {userid} representing a user and {fileid} representing a file inside that user context
Frontend
htmx was used to enhance component based template generation from a-h/temple, the both of them work really well together since it is trivial to make use of rendering conditional components or full sides with just a simple header check, in addition u can save a lot of computing power when not even fetching unneeded data in case u just need sub components:
func (s *Server) GetLatestFiles(w http.ResponseWriter, r *http.Request) response {
u := models.GetUser(r.Context())
limit, offset := pagination(r)
files, err := s.FileRepository.GetRecentFiles(r.Context(), u, limit, offset)
if err != nil {
return response{err: err}
}
if hxrequest(r) { //if htmx request return file component directly
cmp := components.Wrapper(web.Folders(files, "Latest", limit, offset))
return response{err: cmp.Render(r.Context(), w)}
}
//fetch folders to render full page which contains more stuff then just the fragment
folder, err := s.FileRepository.GetAllFolders(r.Context(), u)
if err != nil {
return response{err: err}
}
cmp := components.Wrapper(views.Index("Latest", folder, "latest"))
return response{err: cmp.Render(r.Context(), w)}
}while in conclusion a nice pair to work together, when ur used to force logic into the frontend to minimize server calls it realy becomes a mess and harder to debug. for example the file uploading is delegated to the frontend using presigned links which cant be done with just htmx so u have to create javascript which just isnt nice in temple if u again dont want to make unnecessary server calls
Vector embeddings
to allow for semantic search, currently all text files are scanned and turned into embeddings. The contents of a document is prepared first. in the first phase it has an llm generate:
- keywords: a list of words a user would potentially use to associate with the document
- summary: a two sentence summary of the content
- metadata: Dates, places, contenttype, contacts, bills or what ever could be relevant based on the content
- tags: simple one sentence words that add in user filters: invoice may payment 2025 work
- folder: based on the list of existing folder names which one could fit / or create a new one
in the second phase embeddings are created for the each of the generated values, and every piece of content is split in to 75 long chunks with a 5 char overlap to the previous chunk. this increases short search term accuracy immensely
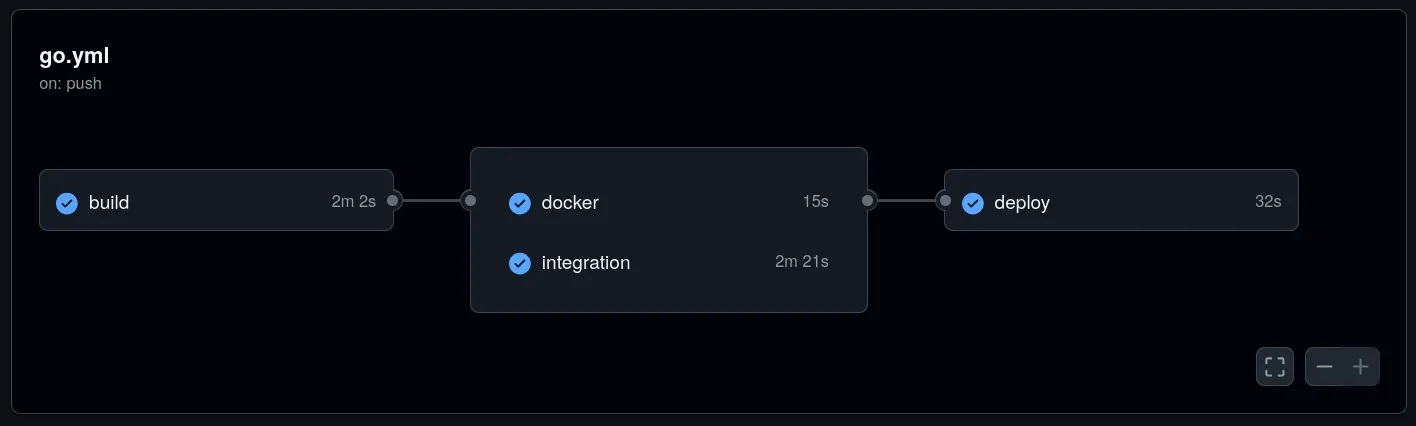
Ci/cd
for integration and deployment is a github actions pipeline used thats run on main push
- it builds the go application
- it builds the docker application
- it runs the go binary, including a postgres db and runs playwright integration tests testing on a majority of browsers the uploading, searching, downloading, deleting of files
- if the docker build and integration tests are complete it pushes the container to the docker-hub repository which is later deployed using gitOps (argocd) manually. in a previous iteration it was set up inside the repository but due to having one repository for all deployments now its no longer allowed due to security risks
Performance testing
Since using heavy caching for almost everything and delegating stuff like object management to the s3 provider, is the application in a simple locust test the service was able to serve 100s of requests every second without the user noticing any latency.
on the other hand the searching through the documents is comparativley slow, its probaly due to missing db indexes in the vector space and the sheer amount of items considering uploading a single book creats thousands of embeddings, and the extra round trip off embedding the value using openais api. there’s also 0 caching in either the embedding request themself or the results